





Programar un sitemap en PHP
Como ya comentamos en el post «¡A navegar grumetes!: Rastreo e indexación, primer contacto con Google«, los buscadores siguen los enlaces de una web para saltar de una página a otra.
Por lo tanto, si no tenemos una estructura de enlaces internos bien desarrollada, puede que los buscadores no sean capaces de llegar a todo nuestro contenido.
Para solventar el problema hay dos estrategias que debemos seguir, la que vimos en el post Internal Linking y la que os vamos a contar ahora: Desarrollar un sitemap.xml.
¿Qué es exactamente un sitemap.xml?
Hace unos años era muy común ver, a pie de página, los «mapas de sitio«. Eran secciones dentro de una web, dedicadas exclusivamente a listar todo el árbol de categorías, secciones y páginas de las que se componía.
Con el tiempo, Google se dio cuenta de lo útil que resultaban estos «mapas de sitio» para conocer el contenido de las páginas, así que creó un estándar basándose en el lenguaje XML. Así, sus bots rastreadores podrían entender con mayor facilidad el contenido a indexar.
Este estándar era una lista de todos los enlaces que contenía una web, junto a su fecha de actualización, su relevancia o peso dentro de la web, y su autoría. Con el tiempo, el resto de buscadores también incorporaron este avance.
Hoy día, ese archivo, que hace las veces de mapa de sitio bajo el lenguaje XML, se llama sitemap.xml y es uno de los puntos más importantes para el posicionamiento SEO.
Es público y casi siempre se ubica en dominio.com/sitemap.xml
El nuestro está en https://www.loopeando.com/sitemap.xml
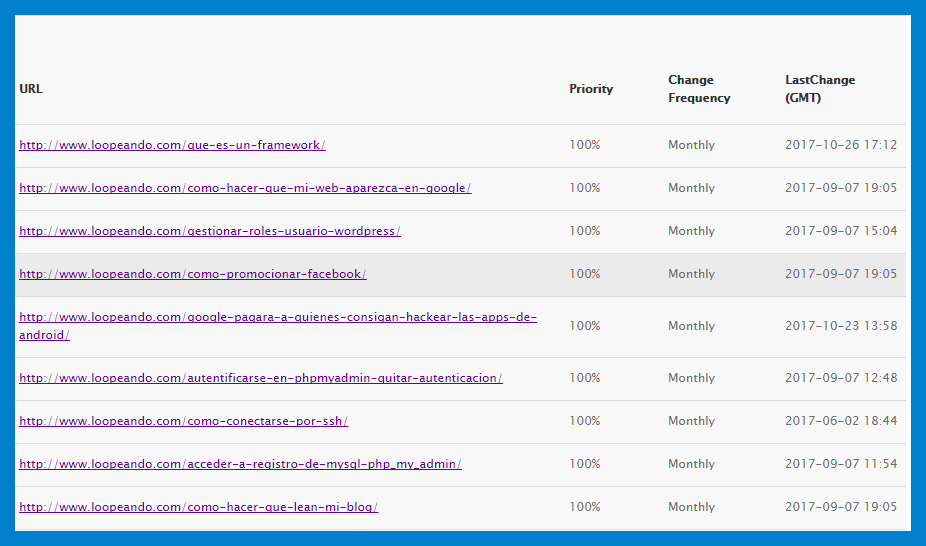
Tengo WordPress, ¿Cómo crear un sitemap?
Hay múltiples plugins que nos permiten automatizar esta tarea, entre los más populares están:
Una vez descargado uno de esos plugins, y creado el sitemap, debemos notificar a Google de su existencia haciéndole llegar el enlace a través de Google Search Console. En «¿Cómo concertar una cita con los bots de Google?«, explicamos cómo.
No dispongo de ningún CMS, ¿Hay alguna herramienta para crear un sitemap?
Si tu web no tiene ningún gestor de contenidos popular, o es un desarrollo propio, te recomendamos las siguientes herramientas para que te generen automáticamente un sitemap.xml:
- XML-Sitemap [Visitar Web]
- Online XML Sitemap Generator [Visitar Web]
- Free XML Sitemap Generator [Visitar Web]
Lo único que tendrás que hacer será acceder a cualquiera de ellas, facilitarles la url de tu web, y te dejarán descargar el archivo. A continuación habrás de subirlo a tu web y mostrar a Google la ruta dónde está.
Se programar y quiero crear un sitemap que se actualice en tiempo real
Si acudimos a una web para que nos genere un sitemap de manera automática, tendremos dos problemas:
- El Sitemap generado será estático, por lo que salvo que cada vez que publiquemos o creemos algo en nuestro site, generemos un nuevo sitemap, lo volvamos a subir, etc Con el tiempo quedará desactualizado.
- Habremos perdido la maravillosa oportunidad de aprender a hacerlo nosotros mismos. ¿Cursi? ¡Ni os imagináis lo que se aprende trasteando!
Pues manos a la obra:
Cabecera de un archivo XML:
<?xml version="1.0" encoding="UTF-8"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
Estructura de un sitemap XML:
<url>
<loc>https://www.loopeando.com/</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>hourly</changefreq>
<priority>1</priority>
</url>
Donde entre las etiquetas <loc> debe ir la url a indexar.
Entre las <lastmod> la fecha de la última edición (en nuestro caso, ahora mismo). Si lo vas a poner a mano, el formato es AAAA-MM-DD.
En <changefreq> la frecuencia de actualización, pudiendo ser:
- always
- hourly
- daily
- weekly
- monthly
- yearly
- never
Esto es una guía para los buscadores, que pueden seguir o no. Se recomienda poner tasas de actualización muy bajas para las páginas estáticas (Quienes Somos, Contacto…) y tasas realistamente altas para aquellas donde publiquemos contenido periódico (blog, portada con noticias, foro…).
Y en <priority> la importancia de esa página dentro de la web, siendo 1 la más alta. De esa forma, Google indexará primero las más importantes.
Si nuestro XML fuese estático, deberíamos repetir esa estructura con todas las urls de nuestra web:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://www.loopeando.com/</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>hourly</changefreq>
<priority>1</priority>
</url>
<url>
<loc>https://www.loopeando.com/contacto/</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>yearly</changefreq>
<priority>5</priority>
</url>
<url>
<loc>https://www.loopeando.com/category/actualidad/</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>hourly</changefreq>
<priority>2</priority>
</url>
</urlset>
Sin olvidar la etiqueta de cierre «</urlset>» .
Y lo guardaríamos con el nombre de sitemap.xml, lo subiríamos a la raíz de nuestro site, y listo.
Pero lógicamente, la gracia de hacerlo nosotros por programación, es que el sitemap se actualice sólo. ¿Cómo lo hacemos? Con consultas a la base de datos:
1º Ponemos la conexión con la BBDD:
//Conectamos con la base de datos $config_host = "localhost"; $config_db = "nombre_base_datos"; $config_user = "usuario_base_datos"; $config_password = "contraseña_base_datos"; $link = mysql_connect($config_host, $config_user, $config_password); mysql_select_db($config_db);
2º Creamos una función que nos parsee el texto por si tuviese tildes o cualquier otro caracter no permitido en las urls (ñ, ü, à…):
//Definimos la función que utilizaremos después para formar las urls de la web
function limpiarCadenaa($string){
$string = str_replace (' ','-',$string);
$string = str_replace(array('á', 'à', 'ä', 'â', 'ª', 'Á', 'À', 'Â', 'Ä'),
array('a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a'),
$string);
$string = str_replace(array('é', 'è', 'ë', 'ê', 'É', 'È', 'Ê', 'Ë'),
array('e', 'e', 'e', 'e', 'e', 'e', 'e', 'e'),
$string);
$string = str_replace(array('í', 'ì', 'ï', 'î', 'Í', 'Ì', 'Ï', 'Î'),
array('i', 'i', 'i', 'i', 'i', 'i', 'i', 'i'),
$string);
$string = str_replace(array('ó', 'ò', 'ö', 'ô', 'Ó', 'Ò', 'Ö', 'Ô'),
array('o', 'o', 'o', 'o', 'o', 'o', 'o', 'o'),
$string);
$string = str_replace(array('ú', 'ù', 'ü', 'û', 'Ú', 'Ù', 'Û', 'Ü'),
array('u', 'u', 'u', 'u', 'u', 'u', 'u', 'u'),
$string);
$string = str_replace(array('ñ', 'Ñ', 'ç', 'Ç'),
array('n', 'n', 'c', 'c',),
$string);
//Esta parte se encarga de eliminar cualquier caracter extraño
$string = str_replace(array("\\", "¨", "º", "~", "#", "@", "|", "!", "\"", "·", "$", "%", "&", "/", "(", ")", "?", "'", "¡",
"¿", "[", "^", "`", "]", "+", "}", "{", "¨", "´", ">", "< ", ";", ",", ":", "."),
'',
$string);
return $string;
}
/* FIN LIMPIAR CADENA */
3º Realizamos las consultas pertinentes a la BBDD para formar las urls.
Esta parte ya es muy personal dependiendo de cada web y su estructura de la BBDD. En nuestro caso, la estructura es:
https://www.loopeando.com/seccion/id_entrada/titular_de_la_entrada
Por lo que debemos sacar de cada entrada los parámetros: seccion, id_entrada y titular_de_la_entrada
Nuestro código, por si os da ideas, sería:
//Listamos todas las entradas que se han publicado hasta ahora
$consultanoticias = mysql_query("SELECT * FROM noticias LIMIT 0, 35000");
while ($pintanoticias = mysql_fetch_array($consultanoticias)){
$titulolimpio = limpiarCadenaa(strtolower(utf8_encode($pintanoticias['titulo'])));
//Formamos el nombre de la sección donde está publicada
$seccion = $pintanoticias['seccion'];
$consultaseccion = mysql_query("SELECT * FROM secciones WHERE id ='$seccion'");
//Verificamos que el resultado de la consulta existe, pues hay noticias antiguas cuyas secciones ya no existen
if (mysql_num_rows($consultaseccion) > 0){
while ($pintaseccion = mysql_fetch_array($consultaseccion)){
if ($pintaseccion['titulo'] ==""){
$seccionlimpia = "secciones";
}else{
$seccionlimpia = limpiarCadenaa(strtolower(utf8_encode($pintaseccion['titulo'])));
}
}
//Las añadimos al XML
$xml .='<url>
<loc>https://www.loopeando.com/'.$seccionlimpia.'/'.$pintanoticias['id'].'/'.$titulolimpio.'</loc>
<lastmod>'.date("Y-m-d",strtotime($pintanoticias['fecha_modificacion'])).'</lastmod>
<priority>0.5</priority>
</url>';
}
}
De manera que todo el código quedaría de la siguiente manera:
<?php
//Conectamos con la base de datos
$config_db = "nombre_base_datos";
$config_user = "usuario_base_datos";
$config_password = "contraseña_base_datos";
$link = mysql_connect($config_host, $config_user, $config_password);
mysql_select_db($config_db);
$link = mysql_connect($config_host, $config_user, $config_password);
mysql_select_db($config_db);
//Definimos la función que utilizaremos después para formar las urls de las noticias
function limpiarCadenaa($string){
$string = str_replace (' ','-',$string);
$string = str_replace(array('á', 'à', 'ä', 'â', 'ª', 'Á', 'À', 'Â', 'Ä'),
array('a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a'),
$string);
$string = str_replace(array('é', 'è', 'ë', 'ê', 'É', 'È', 'Ê', 'Ë'),
array('e', 'e', 'e', 'e', 'e', 'e', 'e', 'e'),
$string);
$string = str_replace(array('í', 'ì', 'ï', 'î', 'Í', 'Ì', 'Ï', 'Î'),
array('i', 'i', 'i', 'i', 'i', 'i', 'i', 'i'),
$string);
$string = str_replace(array('ó', 'ò', 'ö', 'ô', 'Ó', 'Ò', 'Ö', 'Ô'),
array('o', 'o', 'o', 'o', 'o', 'o', 'o', 'o'),
$string);
$string = str_replace(array('ú', 'ù', 'ü', 'û', 'Ú', 'Ù', 'Û', 'Ü'),
array('u', 'u', 'u', 'u', 'u', 'u', 'u', 'u'),
$string);
$string = str_replace(array('ñ', 'Ñ', 'ç', 'Ç'),
array('n', 'n', 'c', 'c',),
$string);
//Esta parte se encarga de eliminar cualquier caracter extraño
$string = str_replace(array("\\", "¨", "º", "~", "#", "@", "|", "!", "\"", "·", "$", "%", "&", "/", "(", ")", "?", "'", "¡",
"¿", "[", "^", "`", "]", "+", "}", "{", "¨", "´", ">", "< ", ";", ",", ":", "."),
'',
$string);
return $string;
}
/* FIN LIMPIAR CADENA */
//Iniciamos el xml con su codificación y su certificación de referencia
$xml = '<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">';
//Pintamos las secciones fijas
$xml .='<url>
<loc>https://www.loopeando.com/</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>hourly</changefreq>
<priority>1</priority>
</url>';
$xml .='<url>
<loc>https://www.loopeando.com/empleo</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>';
$xml .='<url>
<loc>https://www.loopeando.com/portada</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>';
$xml .='<url>
<loc>http://cursos.loopeando.com/index.html</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>';
$xml .='<url>
<loc>https://www.loopeando.com/noticias</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>';
$xml .='<url>
<loc>https://www.loopeando.com/hemeroteca</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>';
$xml .='<url>
<loc>https://www.loopeando.com/rss.feeds</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>daily</changefreq>
<priority>0.8</priority>
</url>';
$xml .='<url>
<loc>https://www.loopeando.com/legal.php</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>';
$xml .='<url>
<loc>https://www.loopeando.com/contacto</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>monthly</changefreq>
<priority>0.6</priority>
</url>';
$xml .='<url>
<loc>https://www.loopeando.com/acceso-empresas</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>monthly</changefreq>
<priority>0.6</priority>
</url>';
$xml .='<url>
<loc>https://www.loopeando.com/acceso-candidatos</loc>
<lastmod>'.date("Y-m-d").'</lastmod>
<changefreq>monthly</changefreq>
<priority>0.6</priority>
</url>';
//Listamos todas las noticias que se han publicado hasta ahora
$consultanoticias = mysql_query("SELECT * FROM noticias LIMIT 0, 35000");
while ($pintanoticias = mysql_fetch_array($consultanoticias)){
$titulolimpio = limpiarCadenaa(strtolower(utf8_encode($pintanoticias['titulo'])));
//Formamos el nombre de la sección donde está publicada
$seccion = $pintanoticias['seccion'];
$consultaseccion = mysql_query("SELECT * FROM secciones WHERE id ='$seccion'");
//Verificamos que el resultado de la consulta existe, pues hay noticias antiguas cuyas secciones ya no existen
if (mysql_num_rows($consultaseccion) > 0){
while ($pintaseccion = mysql_fetch_array($consultaseccion)){
if ($pintaseccion['titulo'] ==""){
$seccionlimpia = "secciones";
}else{
$seccionlimpia = limpiarCadenaa(strtolower(utf8_encode($pintaseccion['titulo'])));
}
}
//Las añadimos al XML
$xml .='<url>
<loc>https://www.loopeando.com/'.$seccionlimpia.'/'.$pintanoticias['id'].'/'.$titulolimpio.'</loc>
<lastmod>'.date("Y-m-d",strtotime($pintanoticias['fecha_modificacion'])).'</lastmod>
<priority>0.5</priority>
</url>';
}
}
//Cerramos el XML
$xml .='</urlset>';
header('Content-type:text/xml;charset:utf8');
echo $xml;
?>
Y por supuesto, ahora al ser dinámico, no debemos olvidarnos de guardarlo como sitemap.php, subirlo a la raíz de nuestro site y mostrar a Google la ruta dónde está.
¿Te ha sido de utilidad esta entrada? ¡Compártela para que también le sirva a tus amigos!



Escribir comentario